Take a read about real-live experience coming from SQL Server migration project I participated in. We migrated from SQL Server 2008 R2 standalone servers into SQL Server 2016 in Failover Cluster Instances (FCI).
Watch the full presentation – Polish language only!
Intro

The environment is a private cloud dedicated to one application using SQL Server 2008 R2. It is delivered in SaaS model to over 1K customers (databases) all over the world. Hence, the cloud consists of over a dozen data centers located in three geographically spread regions.
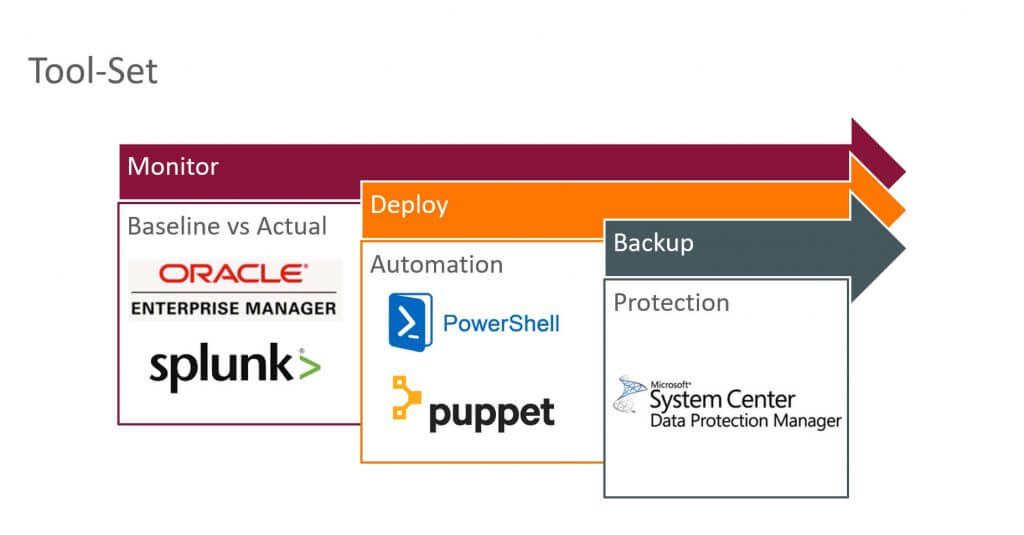
Tool-set: PowerShell, Puppet, Data Protection Manager, Oracle Enterprise Manager, Splunk
Primary target: HA architecture supporting especially operations activities e.g. host patching.
Secondary target: Modernization of disaster recovery environment.
Challenges: Migration to SQL Server 2016 / Windows 2012 considering resources limits in current environment.
Limitations: Use existing infrastructure (hardware & virtualization), defined Tool-Set
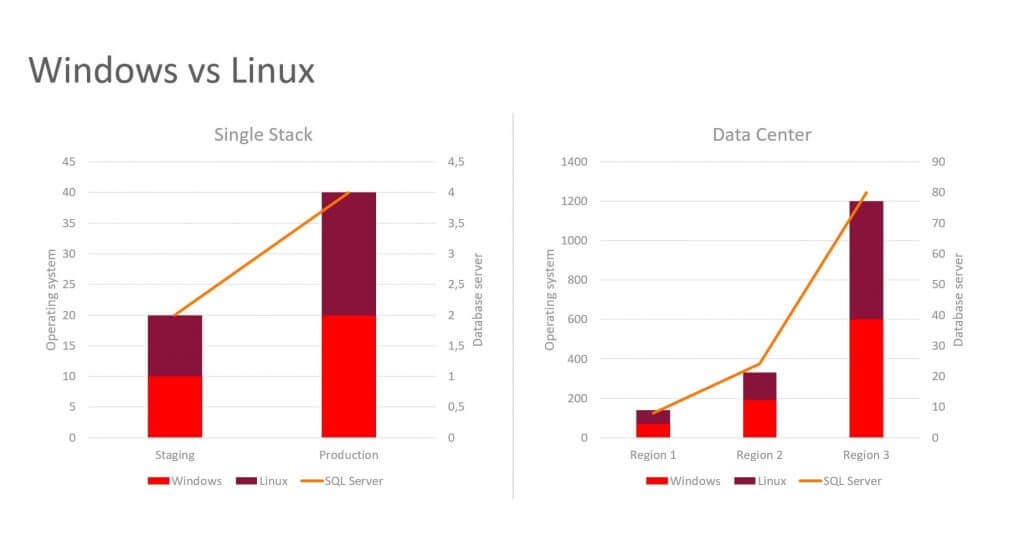
Single stack virtual machines:
- around 30 windows hosts (10 for staging – 2 database servers, 20 for production – 2-4 database servers)
- around 30 Linux hosts (10 for staging, 20 for production)
Data center virtual machines:
- Region 1: 70 Windows (8 database servers), 70 Linux
- Region 2: 190 Windows (24 database servers), 140 Linux
- Region 3: almost 600 Windows (80 database servers), over 600 Linux
In summary: 900 Windows (112 database servers), over 800 Linux
Preparation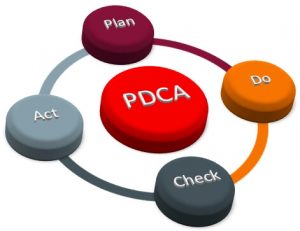
We followed PLAN-DO-CHECK-ACT (PDCA) cycle. Choosing that way was very beneficial. As a result, we managed to find out and correct wrong assumptions before they hit us. We went through several PDCA iterations, which resulted in PDCA outcomes.
Plan
Firstly, we evaluated existing environment, paying special attention to the configuration of the SQL server. The current specification of the database server looks like this:
- 32 GB RAM
- 3 – 8 vCPUs
- Single SQL Server instance
- min server memory = 2 GB
- max server memory = 27 GB
- Avg. 50 databases
We considered the following changes for implementation:
- Architecture: Always On Availability Groups vs Failover Cluster Instances
- Operating system upgrade: In-place vs out of place
- SQL server version: 2012 vs 2014 vs 2016
- Diagnostic tools: Extended Events vs SQL Profiler
Do
Secondly, we made proof of concept in isolated test environment. Initially, our choice of configuration was as follows:
- Architecture: Always On Availability Groups
- Operating system upgrade: In-place
- SQL server version: 2012
- Diagnostic tools: Extended Events
It seemed to be feasible, but it turned out to be untrue.
Check
Thirdly, we validated and thoroughly tested the entire configuration from both operational and development perspectives. As a result we came up with set of adjustments to be implemented. Furthermore, we spotted several environmental restrictions resulting in blockage for choosing particular option.
Act
Finally, we implemented the changes to the original plan. Always On Availability Groups must have been skipped due to the limited amount of storage as well as concerns about network capacity. In-place operating system upgrade could not be considered after an in-depth analysis of virtual environment management. Out of place upgrade was the only option we could choose from. The assessment of the existing environment took quite long time. Initially, SQL server 2012 was the only available to use. Later, 2014 was released and finally 2016. Since it was certified by the development team, we had no other option but to use the latest database engine on the market. Although the SQL Profiler is deprecated, we choose it as a interim solution. The reason for this is that we had a working solution for collecting traces from all SQL instances. It could have been used the way it has been used so far. When we have more free time, the topic of Extended Events will have to be addressed.
PDCA outcomes
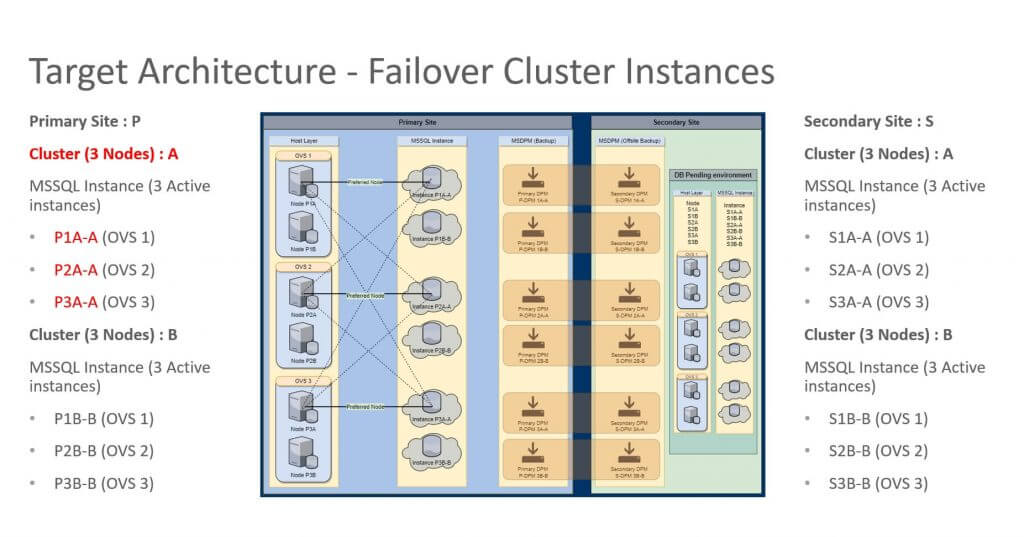
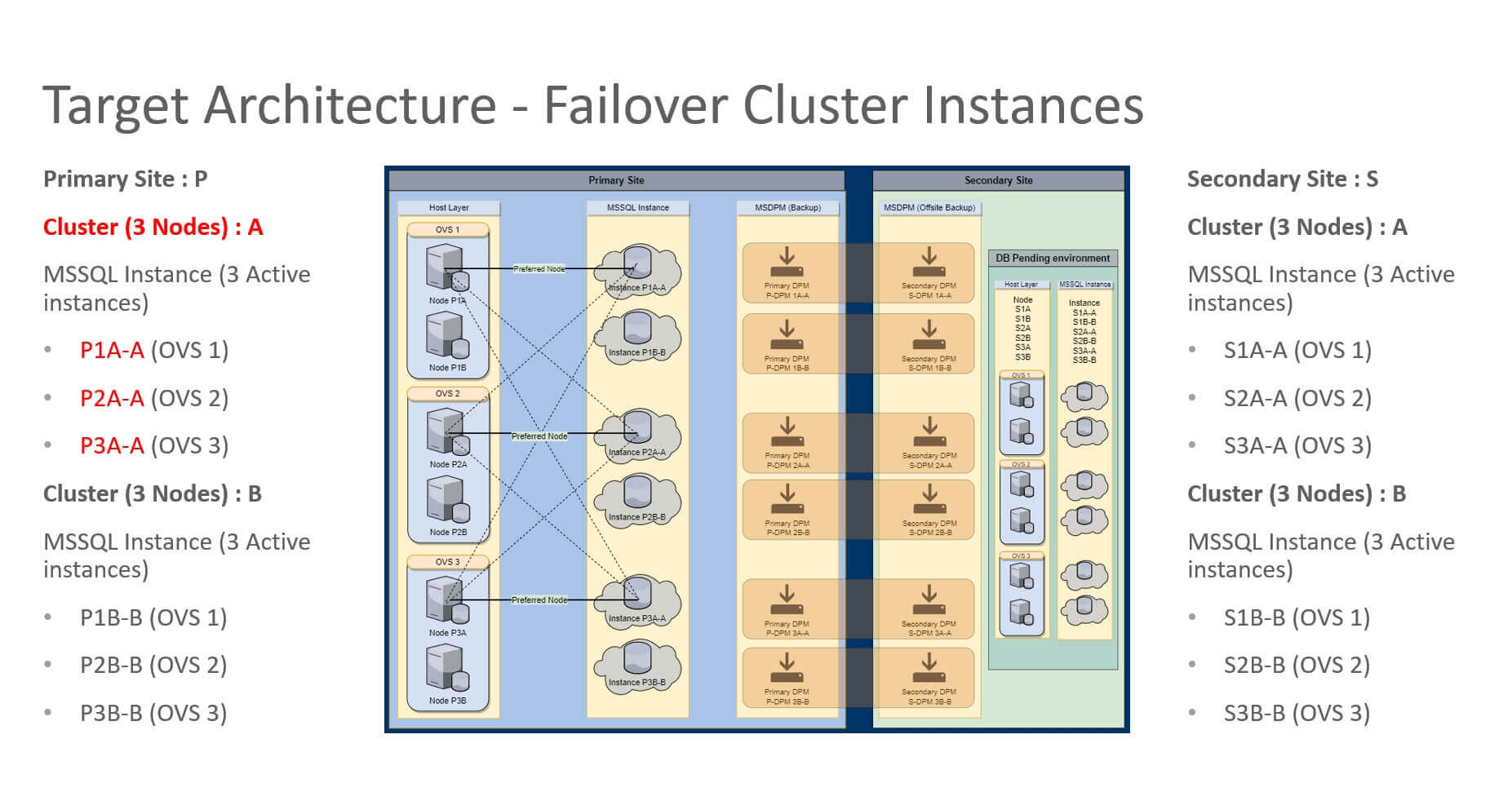
SQL Server 2016 Failover Cluster Instances (FCI) will be run on brand new Windows server 2012 virtual machines. The deprecated SQL Profiler will continue to be used.
Target Failover Cluster Node:
- 48 – 64 GB RAM
- 6 – 10 vCPUs
- 1 – 3 Active SQL Server instances
- min server memory = 14 GB
- max server memory = auto
- Avg. 30 databases
Implementation
After preparing, approving and testing the migration plan in a real test environment we had a long list of activities to perform. Here are some of them – the most crucial ones:
- Perform database distribution base on CPU utilization and storage requirements
- Deploy new clusters with SQL Server 2016 based on latest virtual machine image
- Deploy new System Center Data Protection Manager instances
- Update Puppet module for SQL Server to include the following
- application specific configuration
- PowerSchell scripts for SQL Instance configuration e.g. SQL logins, alerts, jobs, linked servers etc.
- PowerShell scripts and scheduled tasks for: Failover Cluster monitoring, SQL Server memory management
- Prepare PowerShell script for SQL Server memory management
When all the above prerequisites were met, we could start the actual migration of the databases. PowerShell scripts triggered by Windows scheduled task were prepared beforehand. As a result, the whole migration was fully automatic, unattended.
Here are the steps we had taken to migrate single database:
- Get info about the source server
- Stop IIS site
- Detach database
- Copy data and log files
- Attach database
- Start IIS site
- Recycle IIS application pool
- Restart other application services
- Test application health page
- Send email with results
How we monitor the migration:
Basically, we’ve been using two tools for the availability monitoring of the application as well as the database migration progress in question.
Oracle Enterprise Manager (OEM)
The majority of its usage focuses on host monitoring. Hence, we monitor CPU & RAM thresholds. Moreover, disks space utilization. Additionally, we have developed metric extensions using PowerShell scripts. Their main purpose is to alert us about Failover Cluster stability. In general, Oracle Enterprise Manager (OEM) will send us a warning message whenever a human reaction is required. Here You can read more about Oracle Enterprise Manager (OEM)
Splunk
On the other hand, we use splunk not only for warning purposes, but also for data analysis as the work progresses. This allows us to see the data in almost real time. Then we can compare it with historical data as shown in the screenshot below. However, in splunk we collect not only host metrics as we do in OEM, but also more detailed data, such as a set of SQL Server metrics:
Batch Requests/sec, Buffer cache hit ratio, Buffer cache hit ratio base, Free List Stalls/sec, Lazy Writes/sec, Page life expectancy, Page Lookups/Sec, Page Reads/Sec, Page Writes/Sec, Target Server Memory (KB), Total Server Memory (KB), Transactions/sec

Here You can read more about splunk.
Lessons Learned
- For Failover Cluster
- SQL Server Memory must be managed automatically
- MSMQ must be configured as Failover Cluster Resource
- Unstable Availability Groups for Disaster Recovery Site may impact Primary Site
- Fallback from SQL Server 2016 to 2008 R2 is NOT possible
- Mitigation: Restore latest backup for SQL Server 2008 R2 – incorporate data loss
- No adjustments specific to SQL Server 2016 required
- SQL Server Profiler is deprecated
Next steps
- Configure Availability Groups for Disaster Recovery Site
- Replace SQL Server Profiler with Extended Events
- SET COMPATIBILITY_LEVEL = 130


{kind=link}
Comments
Many thanks, this website is very beneficial.
Truly, this is a beneficial webpage.
I haven’t checked in here for a while since I thought it was getting boring, but the last several posts are great quality so I guess I will add you back to my everyday bloglist. You deserve it my friend ?
Excellent post. I was checking constantly this blog and I am impressed! Extremely useful information specifically the last part ? I care for such info a lot. I was looking for this particular information for a long time. Thank you and good luck.
I just want to say I am new to blogging and truly liked this website. Likely I’m likely to bookmark your blog post . You actually come with fantastic stories. Regards for sharing your webpage.
Exceptional post however I was wondering if you could write a litte more on this topic? I’d be very grateful if you could elaborate a little bit further. Bless you!